The Latest from TechCrunch
The Latest from TechCrunch |  |

- TC Teardown: 13 Ways To Get To $10 Million In Revenues (Part I)
- Students Code The Night Away At HackNY’s Student Hackathon
- CrunchGear’s Round-up Of CEATEC 2010 In Japan (12 Highlights)
- We No Longer Live In Actual Countries But Digital Ones
- Why? Because They Can!
- Google’s Self-Driving Car Spotted On The Highway Almost A Year Ago (Oh: And Scoble) [Video]
- World-Changing Awesome Aside, How Will The Self-Driving Google Car Make Money?
- Google Has A Secret Fleet Of Automated Toyota Priuses; 140,000 Miles Logged So Far.
- Meet NELL. See NELL Run, Teach NELL How To Run (Demo, TCTV)
| TC Teardown: 13 Ways To Get To $10 Million In Revenues (Part I) Posted: 10 Oct 2010 07:50 AM PDT
After last month’s TechCrunch Disrupt, and to provide a business companion to the popular "Lean Startup" customer development methodology, this TC Teardown focuses not on how one specific company makes money but rather seeks to provide a breakdown of the main general ways consumer Internet startups try to make money. Consider it a guide to Internet business models. If you are currently thinking about or are in the process of developing your own consumer startup idea, these key business models will help give you a working knowledge of what it takes to get to $10 million in revenues (assuming you have a good product that the market wants). (Before you post in the comments about how unique your startup is, this list is not meant to capture every consumer business permutation. There are always going to be exceptions. And the breakaway companies like Zynga, Groupon, Facebook, Twitter, and Foursquare, to name just a few, inevitably introduce nuances to pre-existing models.) You can think about consumer Internet companies in three major categories. The following three categories of consumer Internet startups and the representative underlying thirteen business models should give you a more than basic understanding of the main drivers of 95 percent of the consumer Internet startups you hear and read about on TechCrunch. The best consumer investors are intimately familiar with these metrics, so make sure you know which business you are in and how you can get to $10 million before meeting with them. The two main points I am trying to convey are 1) the activities needed to monetize each kind of consumer Internet startup are different and 2) the activities are not difficult to understand. Currently there is not a good resource to demystify the various consumer Internet business models. In my effort to reduce these to basics elements, I know I have likely overlooked something obvious. Please feel free to comment or email me at tcteardown at gmail to let me know what I may have overlooked or to introduce your truly unique take on one of the models so that I can update this post and it can be useful to others. You can also view, download, and use each of the below financial models here. The 3 Main Ways Consumer Internet Companies Make Money As a consumer Internet company, you are trying to attract enough potential customers by providing one (or more) of three kinds of products: 1) media, 2) premium services, or 3) access to a physical good. These are not mutually exclusive—a startup can generate revenue from more than one of these sources. For example, many media companies make money off of both advertising and premium services, like LinkedIn. 1. Media: If you are a media company, you are providing free content and collecting purchasing intent so that you can either sell ads, send leads to products or services your audience might be interested in, and/or upsell to a subscription or digital goods. This category is comprised of a large percentage of consumer Internet startups because startup costs are typically the lowest. As has been said many times before, these kinds of companies are cheap to start but expensive to achieve scale. Representative media startups are those creating applications in search, gaming, social networks, new media, video and audio, and lead generation companies. 2. Paid Service: If you provide a paid service, you are trying to attract as many potential consumers to you as cost effectively as possible, get them to pay you for a service, and then work to keep them as paying subscribers for as long as possible. Most startups in this arena follow the "Freemium" strategy, where some content or basic service is provided for free in the hopes of converting a small portion of the free base to paying subscribers. "Freemium" is by no means the only way to acquire customers, but it can usually be the most cost effective means, especially if the service is built upon cheaply produced media or third-party infrastructure providers such as Amazon’s S3, and the variable costs to serve a new customer are minimal. Payments and financial services companies are included here because they provide some services for free or for a fee and also charge businesses a small percentage of each transaction. Representative startups are companies that create premium subscription services, new banks or investment firms, and payment companies. These kinds of companies frequently require more capital than media startups to start, but may need not as much to scale, since they can leverage the cash paid in from consumers. 3. Physical Commerce: If you sell a product that is fulfilled via a warehouse, can be sent via UPS, or is a coupon that can be used to purchase goods and services in the real world, you are running a commerce company. These startups generate revenue for each transaction and need to be disciplined around the efficiency of their warehousing operations, returns and customer service, and the amount spent on sales and marketing. 13 Consumer Internet Business Models Below you can see a chart depicting the 13 consumer Internet business models (with examples), the 3 or 4 key monetization drivers for each, and the scale a company needs to achieve to get to an annual revenue run-rate of $10 million. Of course there are lots of activities companies in these categories need to do well, but these are the most important drivers to building a sustainable business.
The 13 kinds of consumer startups are (in no particular order):
Below is a brief overview of the first four company types with corresponding mini business models so you can see how the key drivers work. The remaining business models will appear later in Part II. Type 1: Search As a search company, you are trying to get as broad an exposure as possible to consumers looking for products and services. The more queries you are able to generate, the more likely a user is to click on one of your paid links. The key metrics for this kind of company are:
These metrics are inter-dependent so the number of uniques per month you need, for instance, will largely be dependent on the average revenue per click you can command. For a company where 5 percent of searchers click on paid links and command $0.35 per click on average, the company needs to have 2.5 million monetizable clicks per month to get to $10 million in revenue. Hunch is a good example of a startup that combines elements of traditional search with a new-kind of service, in this case a personalization engine, to provide more accurate product recommendations, and therefore, hopefully will achieve higher conversion rates and better revenue per click. Type 2: Gaming As I wrote in detail in the Teardown on Zynga, the casual social gaming startup, online gaming companies create entertainment via casual games, fantasy role-playing games, virtual worlds, and mobile games. The idea is to create core intellectual property around a concept, provide a portfolio of games for free, and then upsell a percentage of users to pay for virtual goods. The main drivers of the business are:
As this is a volume business, gaming companies need to achieve at least 5 million monthly average users to have a chance to hit $10 million in revenues. In this last way, social gaming companies, like Zynga and Nexon, combine elements of traditional media with commerce by replacing fulfillment of a physical good with a digital one.
Type 3: Social Network Startups that create media around shared experiences or common interests typically make money from ads and sponsorships, and less frequently, premium services. As a new media company, a social network like MyYearbook (junior high school students) or Dogster (pet lovers), cares about how many unique visitors a month they are attracting, how many ad impressions they are able to display, how much of their inventory they can sell, and the average rate an advertiser will pay. In general, the more focused the social network is on a particular vertical, the higher the CPM rates tend to be. A startup needs to get to several million users and high repeat usage to offset a typically low CPM media buy.
Type 4: "New Media" Platform The hardest to define of all the startup types, and also the hardest to predict their ultimate success, are new media platform companies which create content around new technology-enabled experiences. Many of these companies are commonly thought of as social networks. But Facebook, Twitter, and Foursquare are all examples of startups that require consumers to change current behavior and consume media in a new way. For Facebook it is providing a new way of keeping up-to-date with our social network; for Twitter it is providing a way to interact directly with newsmakers and current events; for Foursquare it is providing a way to stay up-to-date with our friends and family's whereabouts.
Key metrics here are the number of people you can attract to your service (both creating content and consuming it), the number you can convince to change their behavior to create new content (status update, tweet, check-in), and the percent you can monetize in this new format. The great thing about these companies is that if you can convince people to use these new tools and consume the content, you will likely have a fast-growing business that easily surpasses $10 million on very little capital. The challenge is that these companies are typically hit-driven, winner-take-all businesses that require significant capital to scale. And you will likely need to convince media planners and advertisers that creating a new ad format is worth their ad budget.
Editor’s note: Contributor Steven Carpenter regularly writes the TC Teardown column. He was the founder and CEO of Cake Financial, which was sold to E*Trade earlier this year. His last guest post was a teardown of group buying site Groupon.       
|
| Students Code The Night Away At HackNY’s Student Hackathon Posted: 10 Oct 2010 07:46 AM PDT
More than 200 students from 33 universities gathered Saturday afternoon to attend HackNY‘s fall Hackathon at New York University‘s Courant Institute of Mathematical Sciences. Fourteen companies, including Meetup, Aviary and Drop.io, demoed their APIs before students settled into couches and chairs to brainstorm ideas while noshing on catered burritos. HackNY, a non-profit dedicated to getting students involved in the city’s start-up culture, organized the hackathon, which also marks the end of NYU Startup Week, a series of panels and events hosted by the student organization Tech@NYU. Chris Wiggins of Columbia University, Hilary Mason of bit.ly and Evan Korth of NYU founded HackNY in February and held its first hackathon in early April. Winning teams presented their hacks to a sold-out auditorium of more than 700 geeks at the New York Tech Meetup the following week. Tonight, about a dozen ambassadors volunteered to hang out answering programming questions, including David Tisch of TechStars New York, 4Chan‘s Christopher "moot" Poole, Rich Frankel of Track.com and Michael Myers from the Examiner.com. Students hacked overnight, many staying up through the night to code up to the deadline, fueled by caffeine, snacks and ice cream served at 3am. The main criteria for judging is awesomeness, Korth said. “The one thing judges don’t care about is whether or not a hack is commercializable.” Here are a few projects that look interesting so far. Interactive Phone Game Paul Kernfeld, Justin Ardini and David Trejo from Brown University are building an interactive game many people can play using their phone keypads. Players dial into the game using Twilio and control tanks on a large screen by pressing appropriate numbers, essentially using their phones as video game controllers. The game is inspired by the classic Scorched Earth for DOS and allows more people to play simultaneously than would be possible with a normal game console. Hunch Group Recommendations From Columbia University, Kui Tang, Zhehao Mao, Tanay Jaiburia, Sid Nair, Cecilia Schudel and Moses Nakamura are building a recommendation engine for groups using Hunch’s API as a solution to the tedious question of “where should we all eat tonight?” The hack assembles the tastes of each group member, balancing them out to recommend something everyone can agree on. The group plans to place more weight on dislikes than likes to avoid suggesting anything a group member might loathe. Twilio Alarm Clock Ian Jablonowski from Rutgers is building an alarm clock that catches you up on what you missed while you were sleeping. Built using Twilio, Twitter and as many services as Jablonowski can incorporate before deadline, the alarm clock calls you in the morning to tell you what’s happening, what’s in the news, and what events you might be interested in that day. Foursqwhere Tal Safran and Max Stoller of NYU are using Foursquare to log check-in data for NYU buildings. They aim to learn who the university’s main community members are and who is the mayor of NYU as a whole. The team’s hack will track which buildings log the most check-ins and offer badges unique to NYU. The idea is to have any organization be able to find their own community by identifying venues and assigning them to the community. Check out more photos from the hackathon here.       
|
| CrunchGear’s Round-up Of CEATEC 2010 In Japan (12 Highlights) Posted: 10 Oct 2010 06:47 AM PDT  Earlier this week, CrunchGear was at CEATEC 2010, Asia's biggest technology and electronics exhibition, which takes place yearly in Chiba (one hour away from Tokyo). All major Japanese electronics makers showcased their newest products (plus numerous prototypes) at the event, and we condensed 12 highlights from CEATEC into a long list after the jump. Click through for videos and more information on each device you're interested in. Read the rest on CrunchGear. Earlier this week, CrunchGear was at CEATEC 2010, Asia's biggest technology and electronics exhibition, which takes place yearly in Chiba (one hour away from Tokyo). All major Japanese electronics makers showcased their newest products (plus numerous prototypes) at the event, and we condensed 12 highlights from CEATEC into a long list after the jump. Click through for videos and more information on each device you're interested in. Read the rest on CrunchGear.
|
| We No Longer Live In Actual Countries But Digital Ones Posted: 09 Oct 2010 09:47 PM PDT
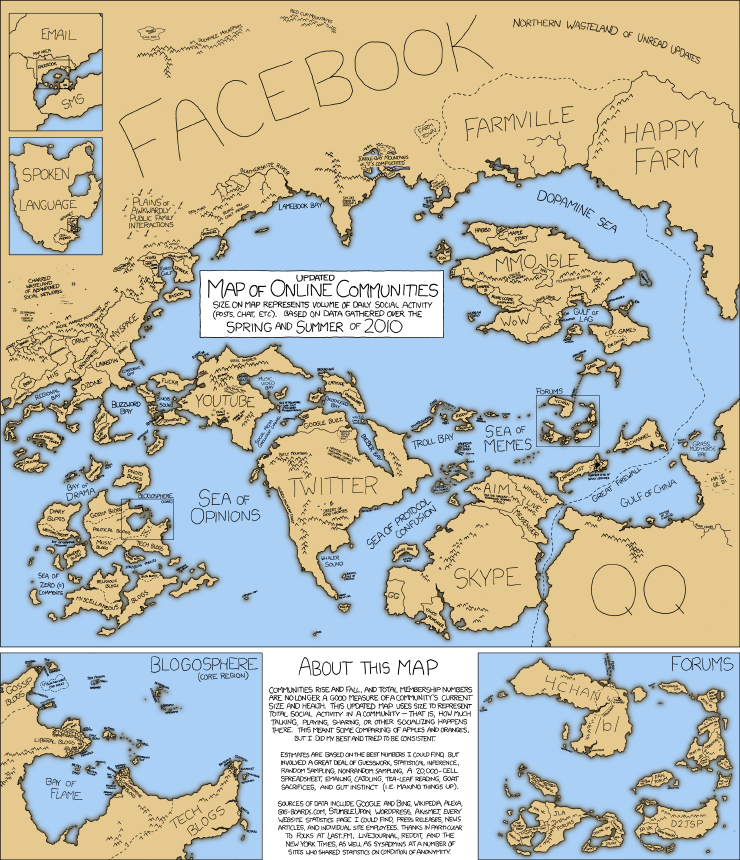
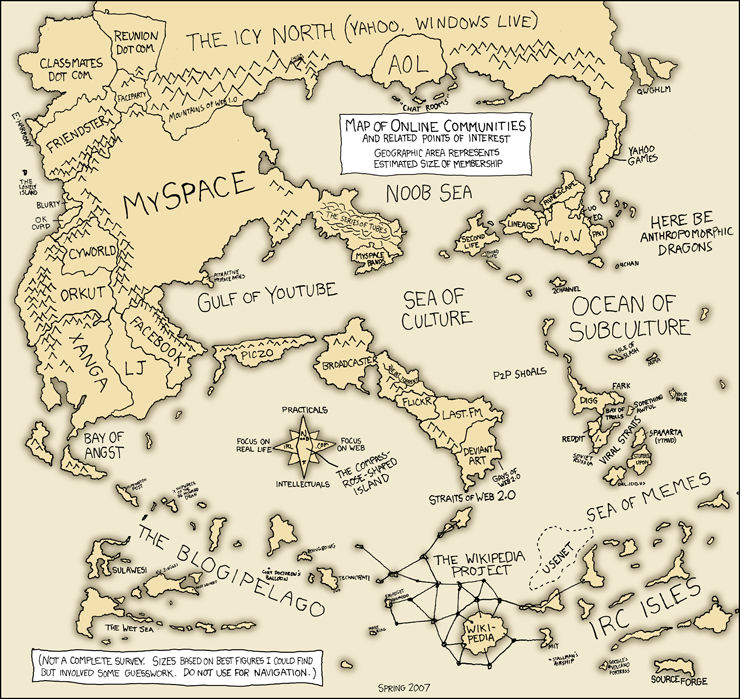
A lot has changed since illustrator Randall Monroe drew up the original XKCD “Map Of Online Communities” in 2007. In testament to how far we as Internet denizens have come, earlier this week XKCD updated its beloved classic to more accurately reflect the rapidly changing online world of 2010. From Monroe in 2007:
Until that day is here (and it’s coming VERY soon, like tomorrow) here’s a quick state of the Internet union; In 2007 the most prominent digital countries were Myspace, Friendster, AOL, Live Journal and Xanga … In 2010? Facebook, Twitter, YouTube, Skype, QQ, Happy Farm and Farmville. Plus ca change, plus c’est la meme chose? Um, Happy Farm? Yeah that’s right, Chinese MMOPG Happy Farm has 228 million active users, making Farmville at 62 million active users the “second biggest browser based social networking centered farming game in the world.” Zoom in for hidden gems like “Social Media Consultant Channel” and “Bieber Bay.” Double zoom in for the island of TechCrunch/Crunch Gear, off the nothern tip of the Tech Blog peninsula. Original 2007 map for comparison, below.
      
|
| Posted: 09 Oct 2010 08:40 PM PDT
And then when we find out that Google is actually working on some seriously science fiction type stuff (self driving cars), New York financial analyst and blogger Henry Blodget asks “Why is Google developing this technology?” I get what Lyons and Blodget are saying. Lyons thinks Zynga, Twitter and Facebook are a waste of engineering resources. Those people could be working on “more important stuff.” And Blodget isn’t anti-self driving cars, he just wants Google to focus on its core business. I say this – who cares! Everyone has a fix for Silicon Valley, but what tends to work best is when people just leave Silicon Valley alone. The crazy (perhaps diseased) manic pipe dreams of entrepreneurs, guided by basic market forces, has gotten us this far. And it will work just as well from now on, too. I love the fact that Google is working on cars that drive themselves. I’m not a shareholder, but if I was I’d still love it. If Larry Page decides this is what he’s passionate about right now, Google definitely doesn’t want him starting some new company to pursue it. Keep it at Google. If it doesn’t work, he’s scratched his itch. If it does, they can spin it off later. In the meantime, Google benefits because people know they’re working on new technology that can change the world, not just how to make more money from keyword ads. There are engineers that may take jobs at Google just knowing that they’re doing stuff like this that otherwise take jobs at one of those companies that Lyons is mocking just to get pre-IPO stock. We want our entrepreneurs to try crazy new things. In a hundred years who knows, Google may be thought of as a car company, not a search company. Crazier things have happened. It wasn’t all that long ago, for example, that Nokia was known as a manufacturer of rubber galoshes. If Blodget had his way, they’d still be at it.       
|
| Google’s Self-Driving Car Spotted On The Highway Almost A Year Ago (Oh: And Scoble) [Video] Posted: 09 Oct 2010 06:19 PM PDT
What Tseitlin captured, of course, was the Google self-driving car. The secret project, which Google revealed for the first time today, is a combination of different technologies developed by Google that will allow a car to drive itself — yes, even on the highway. Google has disclosed that they’ve been testing these cars “recently“, but they’ve clearly been testing them for longer than that, as Tseitlin’s video proves. The fact that these specially-equipped Priuses (and one Audi TT) have racked up over 140,000 miles (1,000 of while have been completely human-free) on the road, suggests a longer cycle of testing as well. One of the most interesting aspects of this whole project is that local authorities were fine with Google road-testing these cars. “We've briefed local police on our work,” Google noted today and said that human beings are always present in the driver’s seat when the cars are on the road just in case a manual override is needed. The only accident over all these months involved someone else rear-ending one of the cars. Tseitlin tells us that he’s actually seen the cars around a few other places as well in the past several months. A commenter on his Facebook post notes the same thing. Google’s secret project has been driving next to many of us all these months and we never ever realized it. That won’t be the case anymore. Watch Tseitlin’s video below.
Update: And none other than Robert Scoble caught the car on video in January 2010 — but he assumed it was the new Street View car. His comment on the video page is funny:
There was a reason they didn’t like him shooting that footage. Also – eyes on the damn road, Robert! This is exactly why we need these cars.
(thx Datadude)       
|
| World-Changing Awesome Aside, How Will The Self-Driving Google Car Make Money? Posted: 09 Oct 2010 03:04 PM PDT
Google’s answer seems to be a “betterment of society” one. “We've always been optimistic about technology's ability to advance society, which is why we have pushed so hard to improve the capabilities of self-driving cars beyond where they are today,” Google engineer Sebastian Thrun, who spearheaded the project (and also runs Stanford’s AI Labs, and co-invented Street View), writes today. That’s great. But Google is still a public company in the business of making money for its shareholders. So one can’t help but wonder what, if any, money-making prospects there are here? “The Google researchers said the company did not yet have a clear plan to create a business from the experiments,” according to the NYT. Further, they quote Thrun as saying that this project is an example of Google’s “willingness to gamble on technology that may not pay off for years.” We know Google has a history of idealism — co-founders Sergey Brin and Larry Page, in particular — but this project cannot come cheap. And the fact is that Google remains basically a one-trick-pony when it comes to making money. They are so reliant on search advertising revenues, that if something suddenly happened to the market, they’d be totally screwed. Android may prove to be their second trick, but it’s not there yet. But there may be more to these automated cars than just an awesomely cool concept. At our TechCrunch Disrupt event a couple weeks ago, Google CEO Eric Schmidt gave a speech about “an augmented version of humanity.” He noted that the future is about getting computers to do the things we’re not good at. One of those things is driving cars, Schmidt slyly said at the time. “Your car should drive itself. It just makes sense," he noted. "It's a bug that cars were invented before computers." If your car can drive itself, a lot of commuters would be freed up to do other things in the car — such as surf the web. One of Google’s stated goals for this project is to “free up people's time”. That matched with Schmidt’s vision of mobile devices being with us all the time every day, likely will translate into more usage of Google. That may sound silly and not worth all the R&D an undertaking as huge as this will require, but don’t underestimate Google. This is a company who cares deeply about shaving fractions of a second off of each search query so that you can do more of them in your waking hours. Imagine if you suddenly had an hour or more a day in your car to do whatever you wanted because you no longer had to focus on driving? Yeah. Cha-ching.
Or imagine if your on-board maps where showing you Google ads. Or you were watching Google TV in your car since you didn’t have to drive. Or you were listening to Google Music with Google ads. It’s all the same. This automated driving technology would free you up to use more Google products — which in turn make them more money. Make no mistake, Google will enter your car in a big way. And automated driving would up their return in a big way. And, of course, none of this speaks to what, if anything, Google would actually charge for such technology implementation. You would have to believe that if and when it’s available, this automated driving tech would be built-in to cars. Would car manufacturers pay Google for it and pass off some of the costs to customers? Or would this all be subsidized by the above ideas? It’s way too early to get into that, I’m sure. And in 8 years, there will be things out there that we can’t even imagine right now. But it’s interesting to think about. The Google Car. Now, don’t get me wrong, I have little doubt Google is being sincere in their broader hopes for such a technology. Here’s their key blurb on that:
That first part is awesome. If we could halve the number of traffic deaths each year, it would be world-changing. And if energy consumption could be cut, it could re-shape economies and save our future. But again, don’t gloss over the last part. Freeing up those 52 minutes a day to be productive — that’s a lot of potential money for Google. And that’s great too. If Google can spend the time and money working on such amazing technology they should be rewarded for it. There’s no rule that says you shouldn’t be able to make money by changing the world. And Google can’t be praised enough for trying. More:
[images: Dreamworks and TriStar Entertainment]       
|
| Google Has A Secret Fleet Of Automated Toyota Priuses; 140,000 Miles Logged So Far. Posted: 09 Oct 2010 12:58 PM PDT
At our TechCrunch Disrupt event a couple weeks ago in San Francisco, Google CEO Eric Schmidt took the stage to give an impressive speech across a wide range of topics. But the most interesting thing he had to say what about automobiles. “It’s a bug that cars were invented before computers,” he said. “Your car should drive itself. It just makes sense.” Well guess what? Surprise, surprise: Google has been working on a secret project to enable cars to do just that. As they’ve revealed on their blog today, Google has developed a technology for cars to drive themselves. And they haven’t done it on a computer, or in some controlled lab, they’ve been out on California roads testing this out. “Our automated cars, manned by trained operators, just drove from our Mountain View campus to our Santa Monica office and on to Hollywood Boulevard. They've driven down Lombard Street, crossed the Golden Gate bridge, navigated the Pacific Coast Highway, and even made it all the way around Lake Tahoe. All in all, our self-driving cars have logged over 140,000 miles. We think this is a first in robotics research,” Google engineer Sebastian Thrun (the brainchild of the project who also heads the Stanford AI lab and co-invented Street View as well) writes. Further, The New York Times, which has a bit more, says a total of seven cars have driven 1,000 miles without any human intervention (the 140,000 mile number includes occasional human control, apparently). These cars are a modified version of the Toyota Prius — and there is one Audi TT, as well. So how does this work? The automated cars use video cameras, radar sensors, and a laser range finder to locate everything around them (these are mounted on the roof). And, of course, they use Google’s own maps. But the key?
Google says it gathered the best engineers from the DARPA Challenges (an autonomous vehicle race that the government puts on) to work on this project. They also note that these cars never drive around unmanned in the interest of safety. A driver is always on hand to take over in case something goes wrong, and an engineer is always on hand in the car to monitor the software. Google also says they’ve notified local police about the project. So has it worked? Apparently, yes. There has been one accident so far, but it was when someone else rear-ended one of these Google cars. Google notes that 1.2 million people are killed every year in road accidents — they think they can cut this number in half with the tech. It will also cut energy consumption and save people a lot of time. I want this yesterday. This is all kinds of awesome. But don’t get too excited just yet. “Even the most optimistic predictions put the deployment of the technology more than eight years away,” according to NYT. More:
[image via NYT]       
|
| Meet NELL. See NELL Run, Teach NELL How To Run (Demo, TCTV) Posted: 09 Oct 2010 12:18 PM PDT A cluster of computers on Carnegie Mellon’s campus named NELL, or formally known as the Never-Ending Language Learning System, has attracted significant attention this week thanks to a NY Times article, “Aiming To Learn As We Do, A Machine Teaches Itself.” Indeed, the eight-month old computer system attempts to “teach” itself by perpetually scanning slices of the web as it looks at thousands of sites simultaneously to find facts that fit into semantic buckets (like athletes, academic fields, emotions, companies) and finding details related to these nouns. The project, supported by federal grants, a $1 million check from Google, and a M45 supercomputer cluster donated by Yahoo, is trying break down the longstanding barrier between computers and semantics. This is not the first time researchers have tried to tackle one of the great, elusive white whales of the programming world, but as the NY Times points out, the way NELL proactively creates and continues to expand its knowledge base is unique. And yet despite all of NELL’s initiative and innovation, she needs help. She is accurate 80-90% of the time, according to Professor Tom Mitchell, the head of the research team (see our demo with Mitchell above). For that 10-20% where NELL misses the mark the results can be somewhat comical— for example, according to NELL, AOL’s parent company is CarPhone and the Palm Treo is an Apple product. Mitchell and his small team are trying to clean up errors as they surface but with nearly 400,000 facts and counting, it’s a gargantuan task. That’s where the online community comes in. Currently, you can access NELL’s knowledge base, via the “Read The Web” project homepage. Here you can peer into NELL’s brain by searching for terms or download the entire database, if you so desire. The next step is turning readers into pseudo-editors. Starting sometime next month, Mitchell will open NELL ‘s database to anyone who wants to help edit and flag errors. “We’re soon going to be adding some buttons by these beliefs, as you browse, so if you see a mistake you’ll be able to click a button and say I don’t believe this… I think that will be very valuable to us,” Mitchell says. “ While this may remind you of Wikipedia’s model with its crowdsourced method of submission and editing, the NELL community will be tinkering with the content and more importantly, the engine. Every correction helps NELL “learn” about facts, relationships and the mechanics of language, which will help it avoid future mistakes. By unleashing the power of the internet on NELL, the system’s intelligence has a chance to grow exponentially, which will help the CMU researchers achieve one of their ultimate goals: to get computers to read, fully understand and return complete sentences. To help with this process, Mitchell is also looking at alternative avenues to up NELL’s IQ, including gaming mechanics. He gave TechCrunch a first look at an upcoming game he plans to launch called “Polarity,” created by Edith Law, Burr Settles and Luis Von Ahn. In this game, a user will be randomly assigned to another user on the web. Each player will be given a keyword like “longtail salamander,” one user will have to click on the words that describe the keyword, while the other user will have to click on the words that do not describe the keyword. All these answers will feed into NELL’s engine and augment the system’s understanding of relationships.
So why should we care about NELL, a computer system that is still riddled with errors and so far seems pretty useless compared to Wikipedia or Quora? Because the engine behind NELL, and similar computer systems, could dramatically alter our relationship to computers and the web, the way we search (Google’s participation is no coincidence), how we gather information, or get our morning news. Although NELL doesn’t exactly “learn as we do”—- I don’t know many people that scan thousands of webpages simultaneously for statistically relevant information— this project is about helping machines comprehend the world the way we do by building a knowledge base that mimics the ones we (as individuals) spend decades building.       
|







 I just don’t get people who live on the East Coast. On the one hand you’ve got Newsweek’s Dan Lyons
I just don’t get people who live on the East Coast. On the one hand you’ve got Newsweek’s Dan Lyons  In November 2009,
In November 2009, 
 Google made a stunning revelation this morning: the existence of
Google made a stunning revelation this morning: the existence of 

 It all makes sense now.
It all makes sense now.

| You are subscribed to email updates from TechCrunch To stop receiving these emails, you may unsubscribe now. | Email delivery powered by Google |
| Google Inc., 20 West Kinzie, Chicago IL USA 60610 | |